Goal: Predict diabetes status from demographic and clinical risk factors using the NHANES dataset.
Data: National Health and Nutrition Examination Survey collected in the US. Variables include age, BMI, direct cholesterol, marital status, and gender.
Models: Logistic Regression and Random Forest (tidymodels framework).
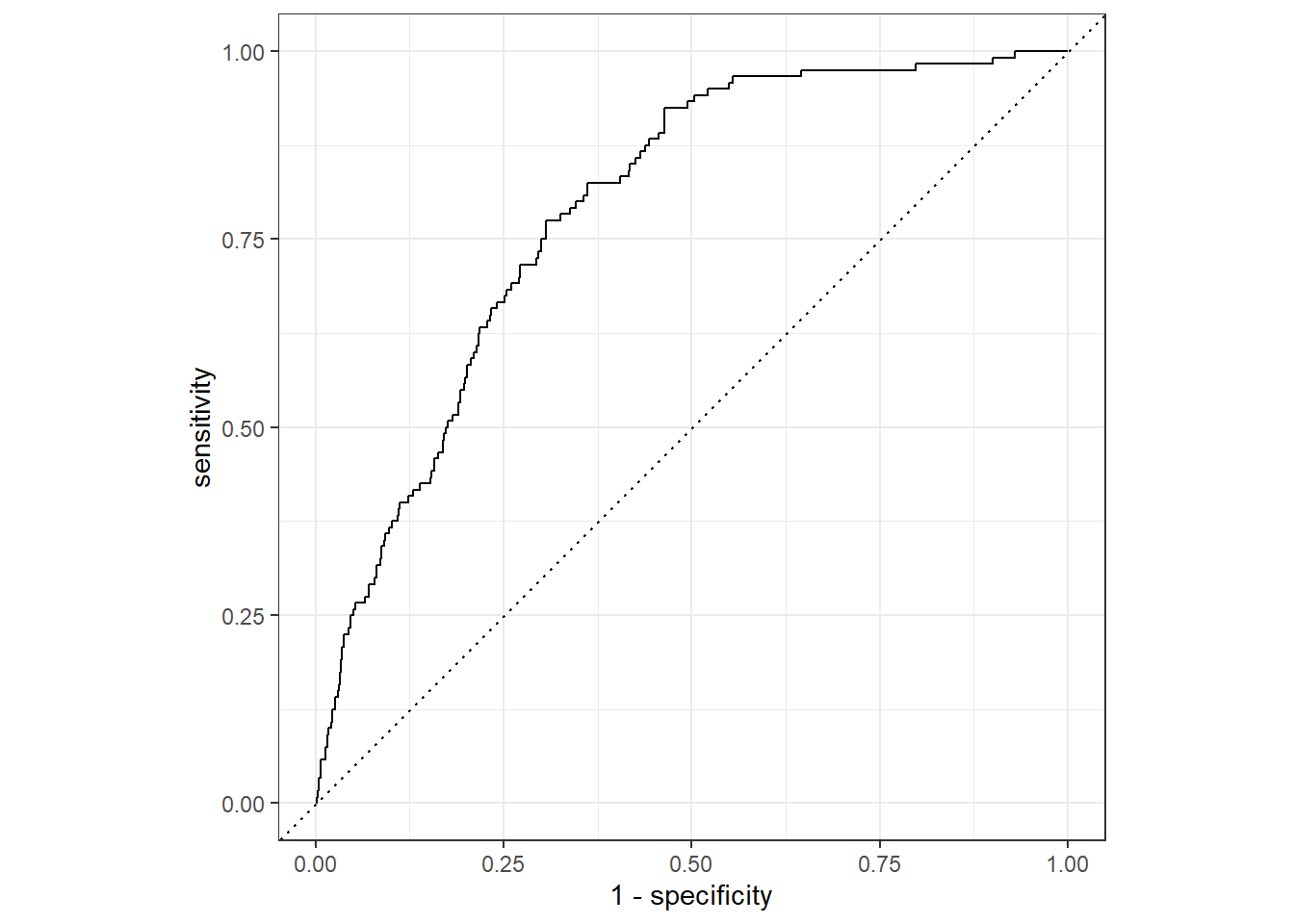
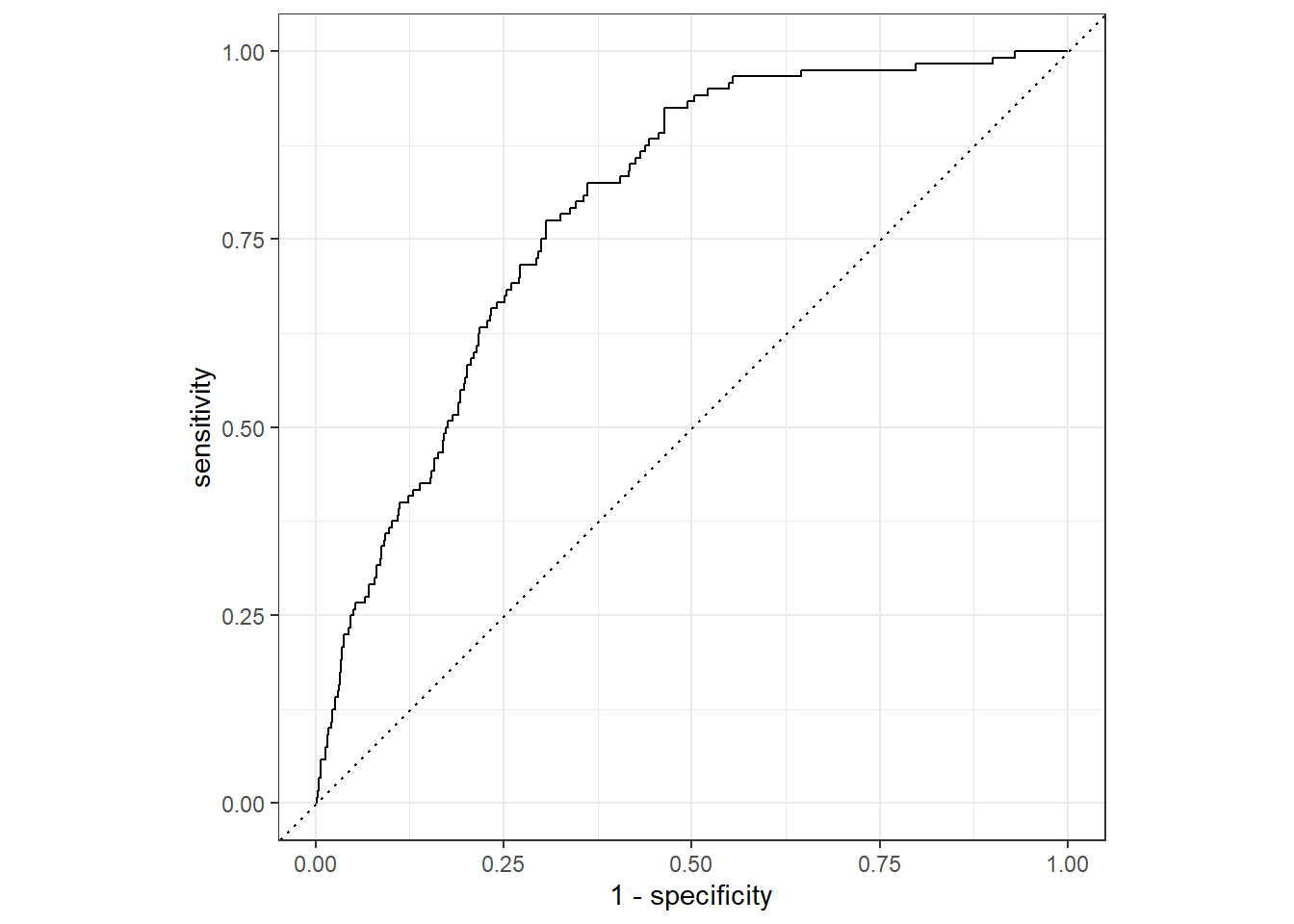
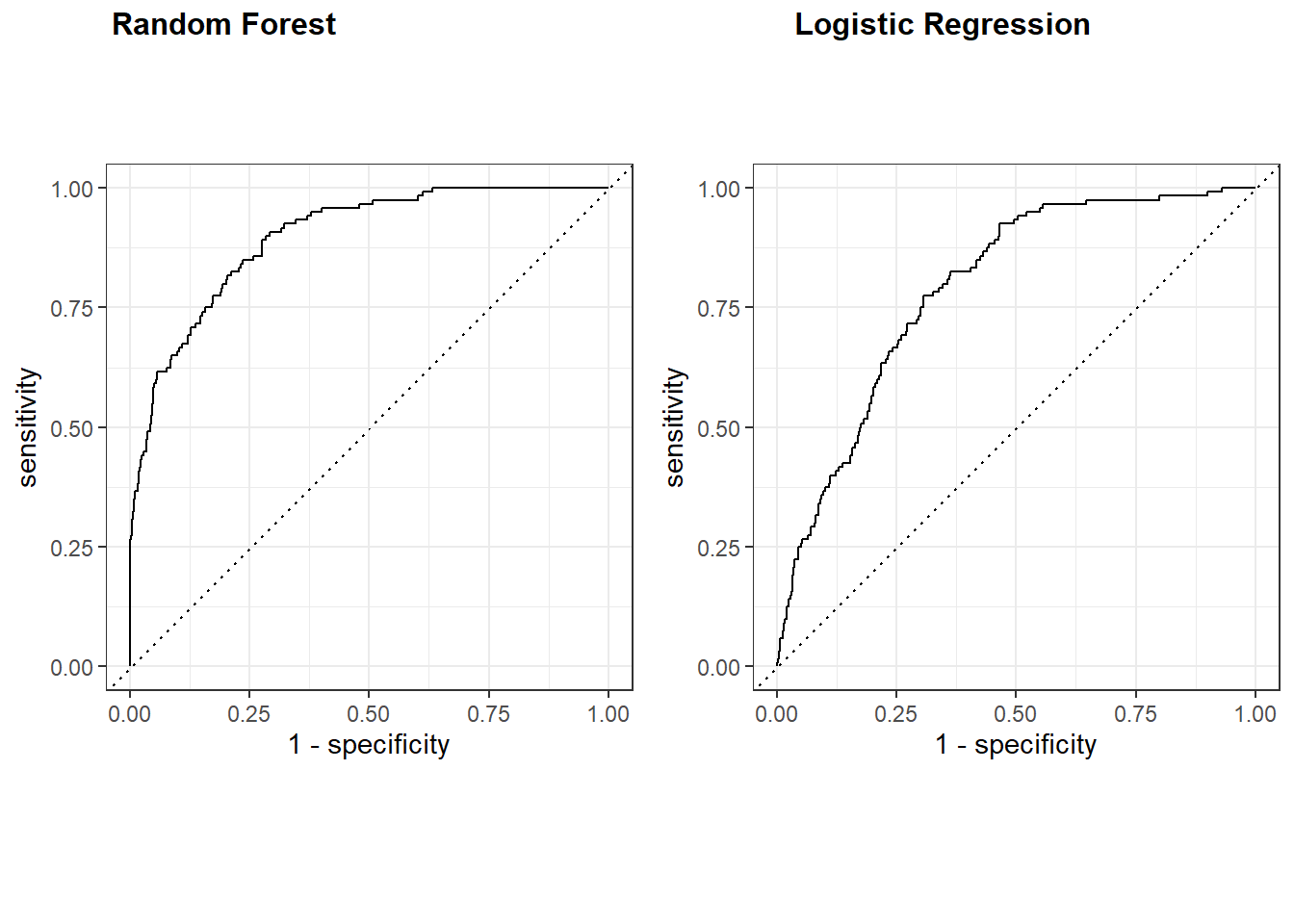
Key Finding: Random Forest outperformed logistic regression across all metrics. Sensitivity improved from 4% (logistic regression) to 34% (Random Forest), with ROC-AUC of 0.89. Both models struggled with the minority class due to class imbalance.
In this project we will use the NHANES dataset to predict diabetes given the available risk factors. The National Health ans Nutrition Survey is a a program in the US designed to assess the health and nutritional status pf adults, and children in the US. The data includes demographic, socio-economic, dietary, and health-related information.
Loading packages including the dataset.
Data Preparation
We are going to save the dataset into the nhanes_df object to maintain the original dataset intact.
nhanes_df<-NHANES |>select(Diabetes,DirectChol,BMI,MaritalStatus,Age,Gender) |>drop_na() |># Assuming variables are missing completely at Randomclean_names()# Changing the levels for appropriate analysisnhanes_df<-nhanes_df |>mutate(diabetes=factor(diabetes, levels =c("Yes", "No"))) |>glimpse()
Rows: 6,786
Columns: 6
$ diabetes <fct> No, No, No, No, No, No, No, No, No, No, No, No, No, No,…
$ direct_chol <dbl> 1.29, 1.29, 1.29, 1.16, 2.12, 2.12, 2.12, 0.67, 0.96, 1…
$ bmi <dbl> 32.22, 32.22, 32.22, 30.57, 27.24, 27.24, 27.24, 23.67,…
$ marital_status <fct> Married, Married, Married, LivePartner, Married, Marrie…
$ age <int> 34, 34, 34, 49, 45, 45, 45, 66, 58, 54, 58, 50, 33, 60,…
$ gender <fct> male, male, male, female, female, female, female, male,…
Train/Test Split
In the code below, we are splitting our data into training and testing sets (0.8, 0.2) and stratify by the diabetes to preserve class proportions.
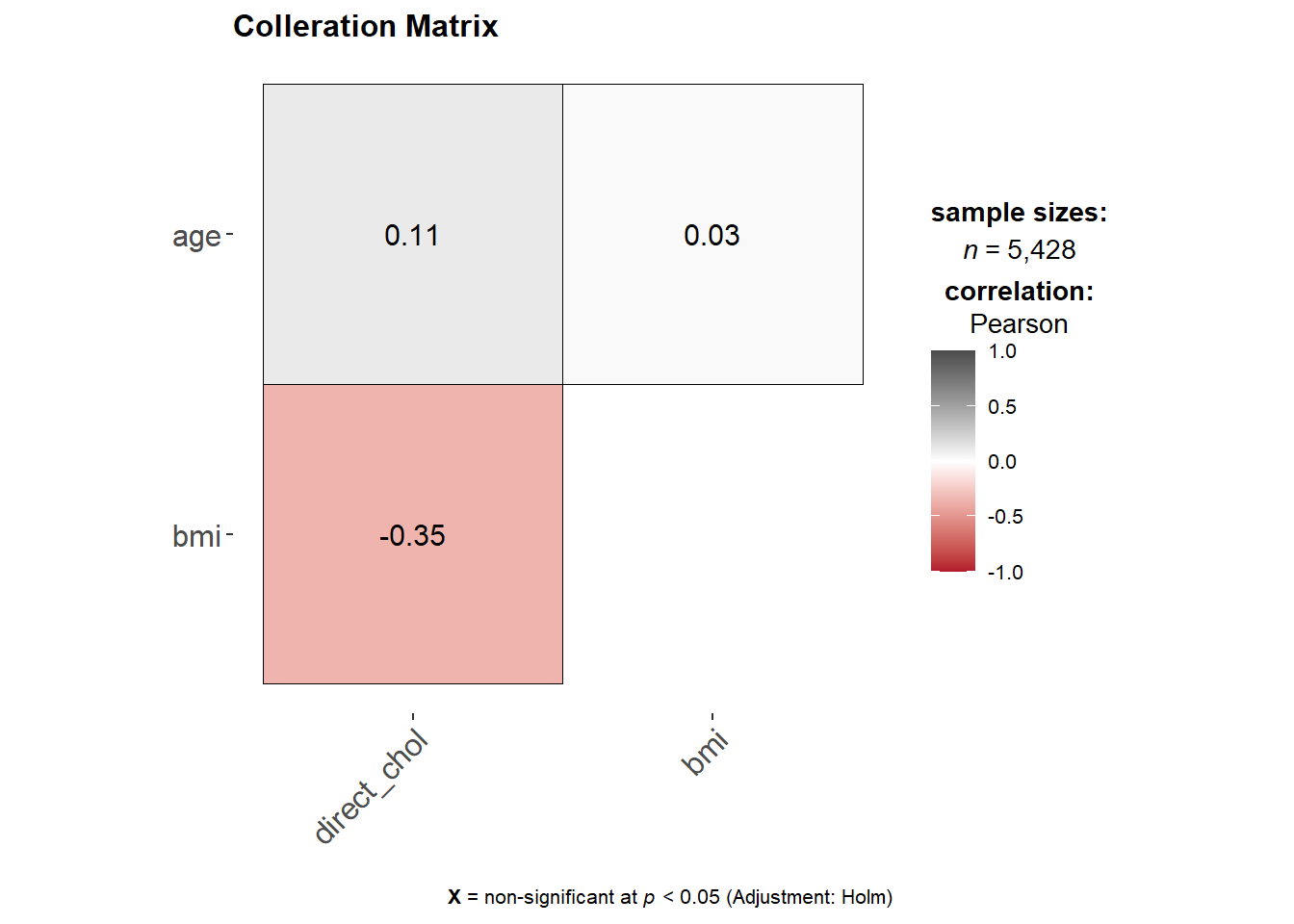
Using the hypothetical threshold of 0.8, we can conclude that the predictors are not collerated. In the code below, we are going to fit both models using the fit function. After which we are going to collect and combine predictions, and load them.
In the code below we are going to specify a recipe object after which we will add steps for engineering our features (feature engineering). The steps are to preprocess the data into a form that will allegedly improve our analysis.
Workflow and Fit
set.seed(123)lr_recipe<-recipe(diabetes~.,data = ml_training) |>step_log(all_numeric()) |>step_normalize(all_numeric()) |>#Centering and scalingstep_dummy(all_nominal(), -all_outcomes())
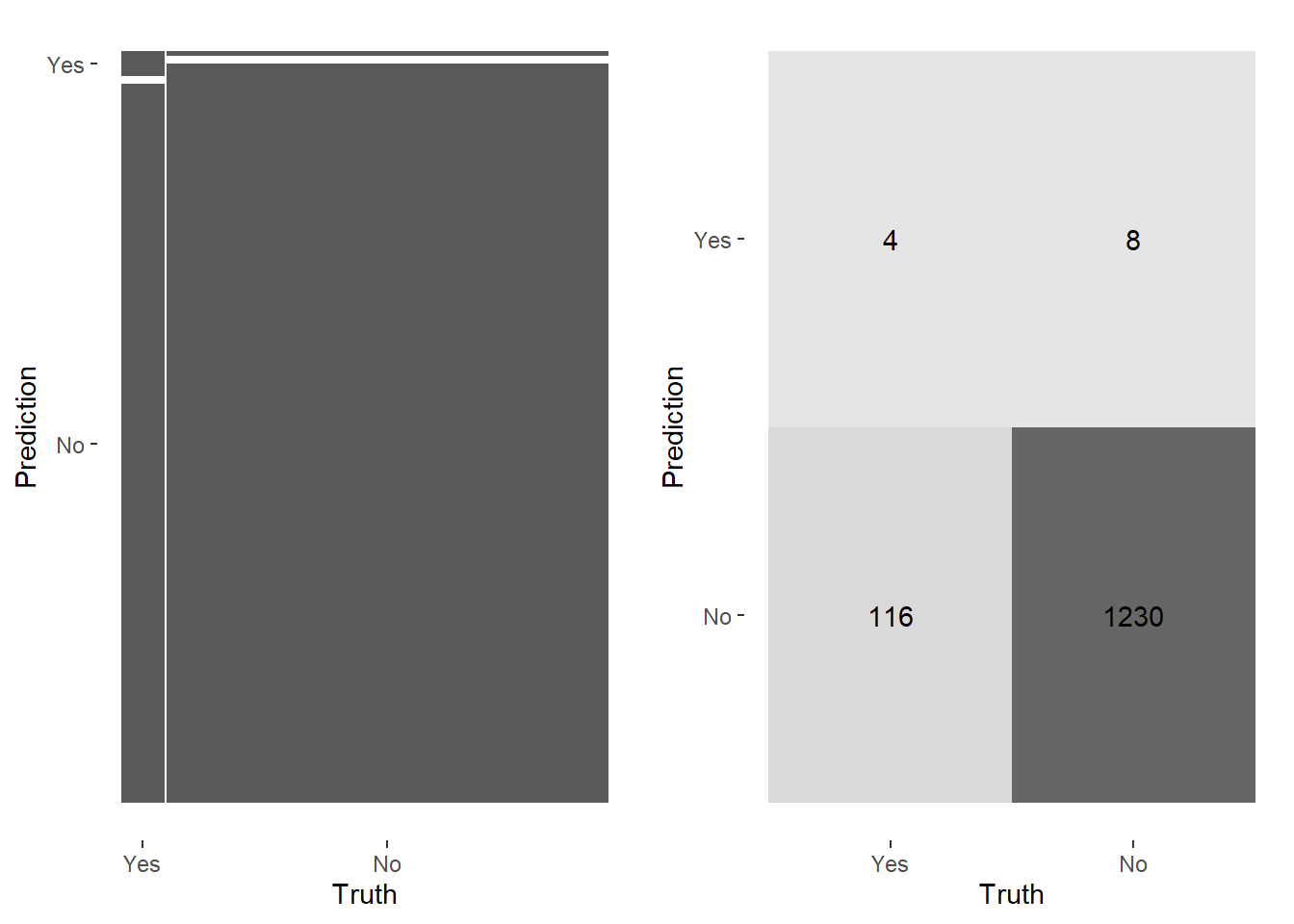
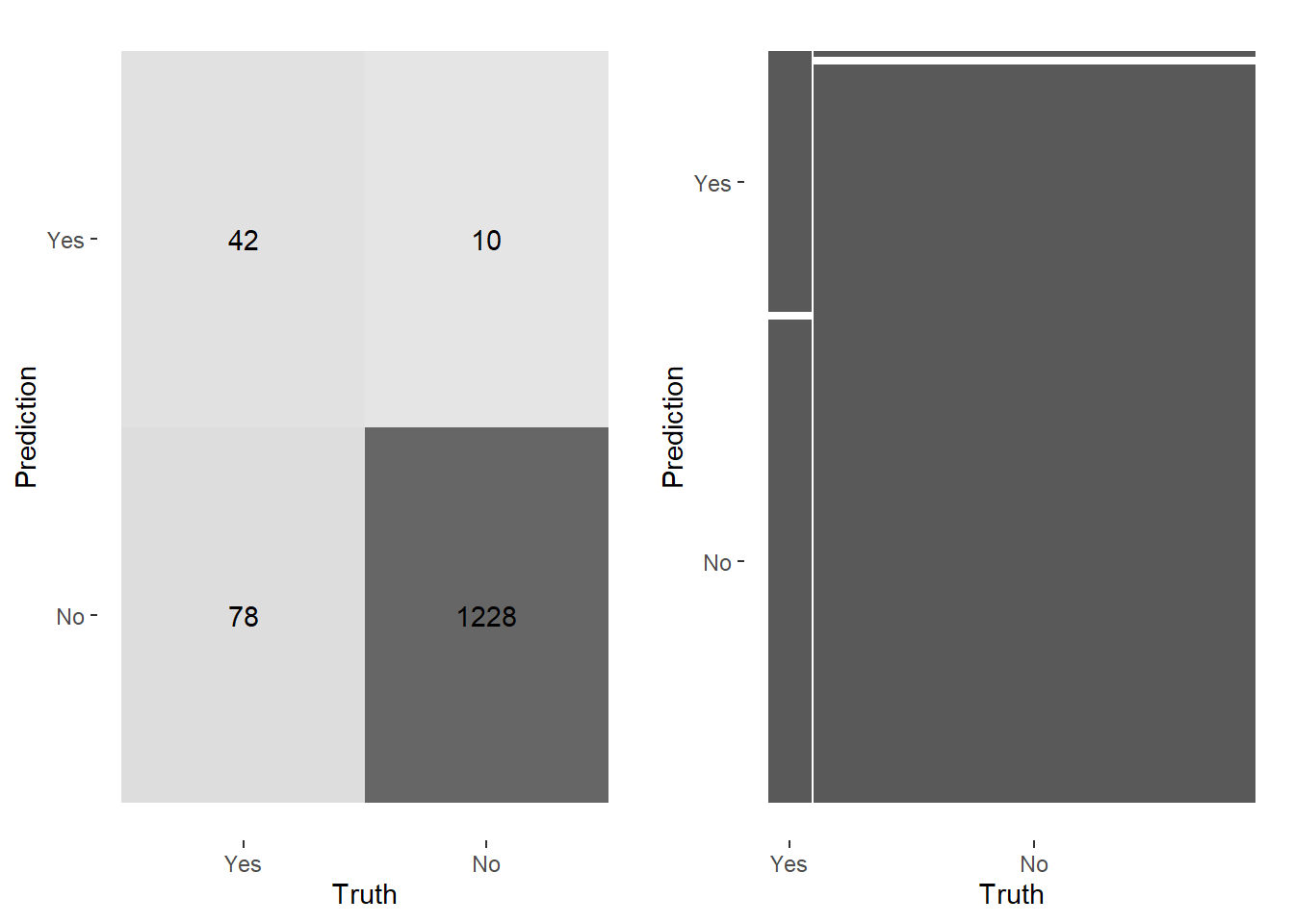
set.seed(123)heatmap_lr<-conf_mat(lr_resultss, truth = diabetes, estimate = .pred_class) |>autoplot(type ="heatmap")mosaic_lr<-conf_mat(lr_resultss, truth = diabetes, estimate = .pred_class) |>autoplot(type ="mosaic")cowplot::plot_grid(mosaic_lr,heatmap_lr)
The 91.1% accuracy is misleading. The model predicts negative cases well (high specificity) but identifies only 4 out of 120 positive cases. Accuracy alone is not a useful metric here due to class imbalance.
Logistic regression failed to correctly identify positive cases. Random Forest offers more flexibility for nonlinear relationships and imbalanced data.
The model predicts this patient does not have diabetes. Given the model’s high specificity, negative predictions are reliable.
Limitations and Next Steps
This analysis skipped hyperparameter tuning (k-fold cross validation) and did not address class imbalance through oversampling (SMOTE) or threshold adjustment. These are the clear next steps for improving sensitivity on the minority class.