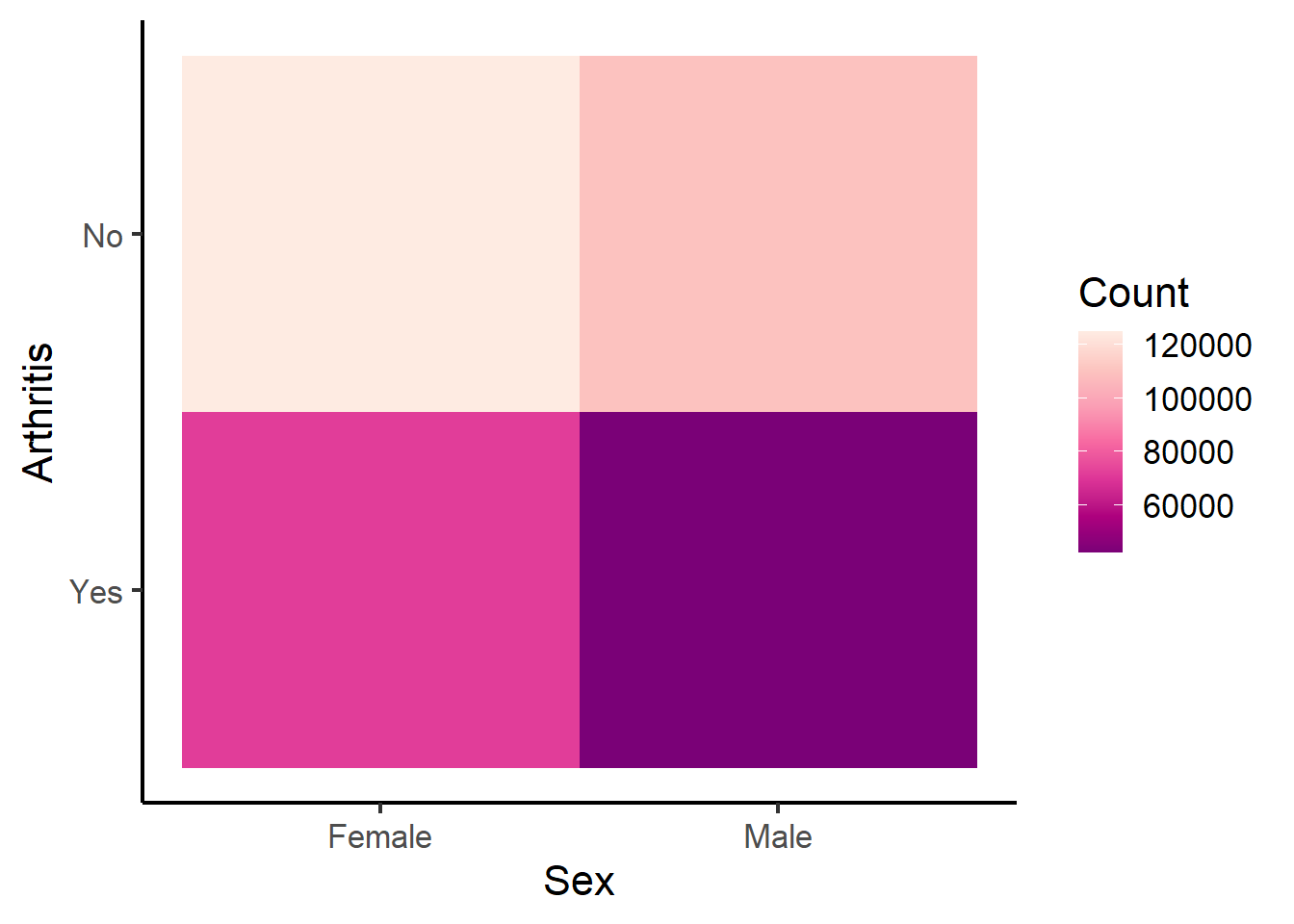
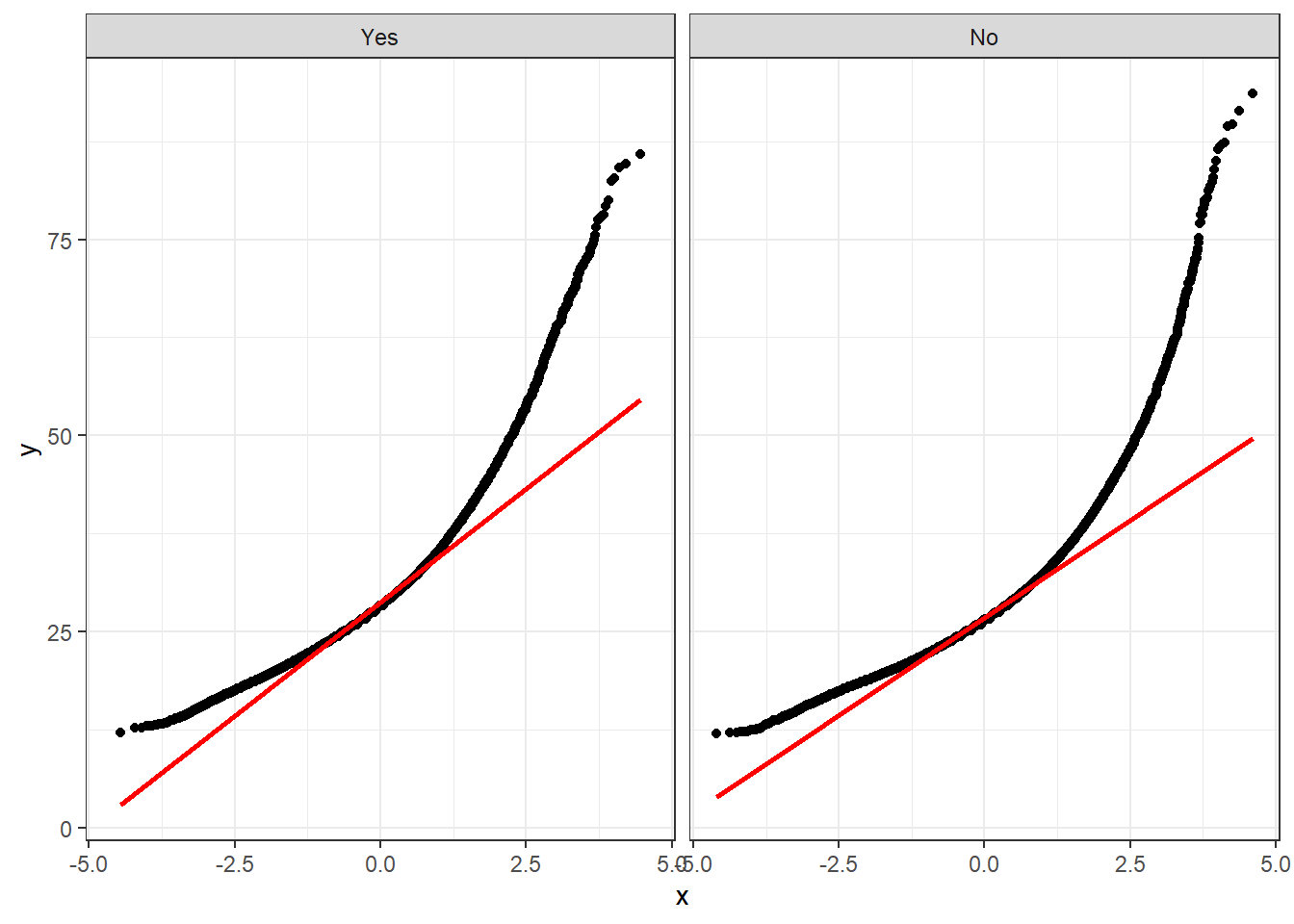
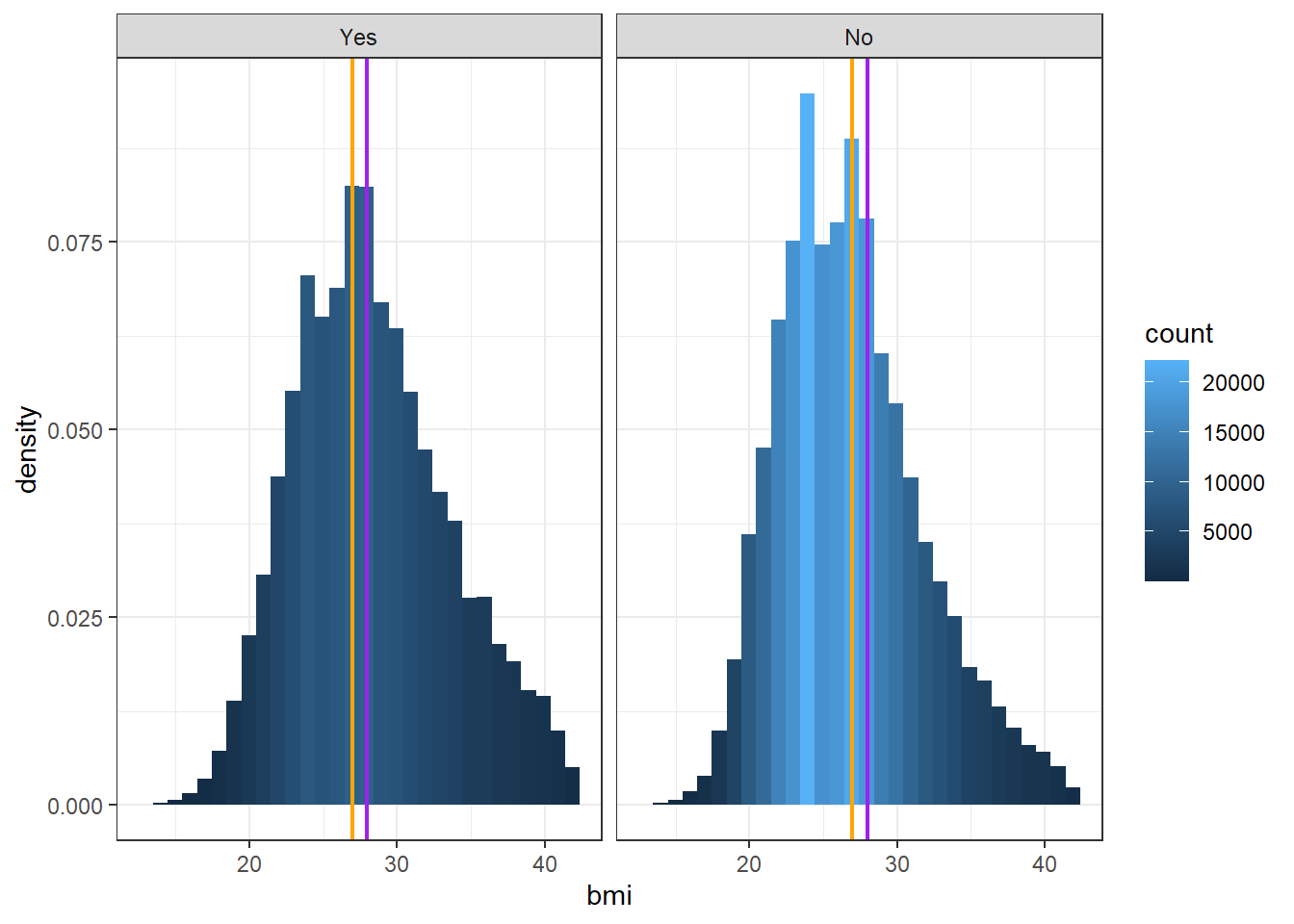
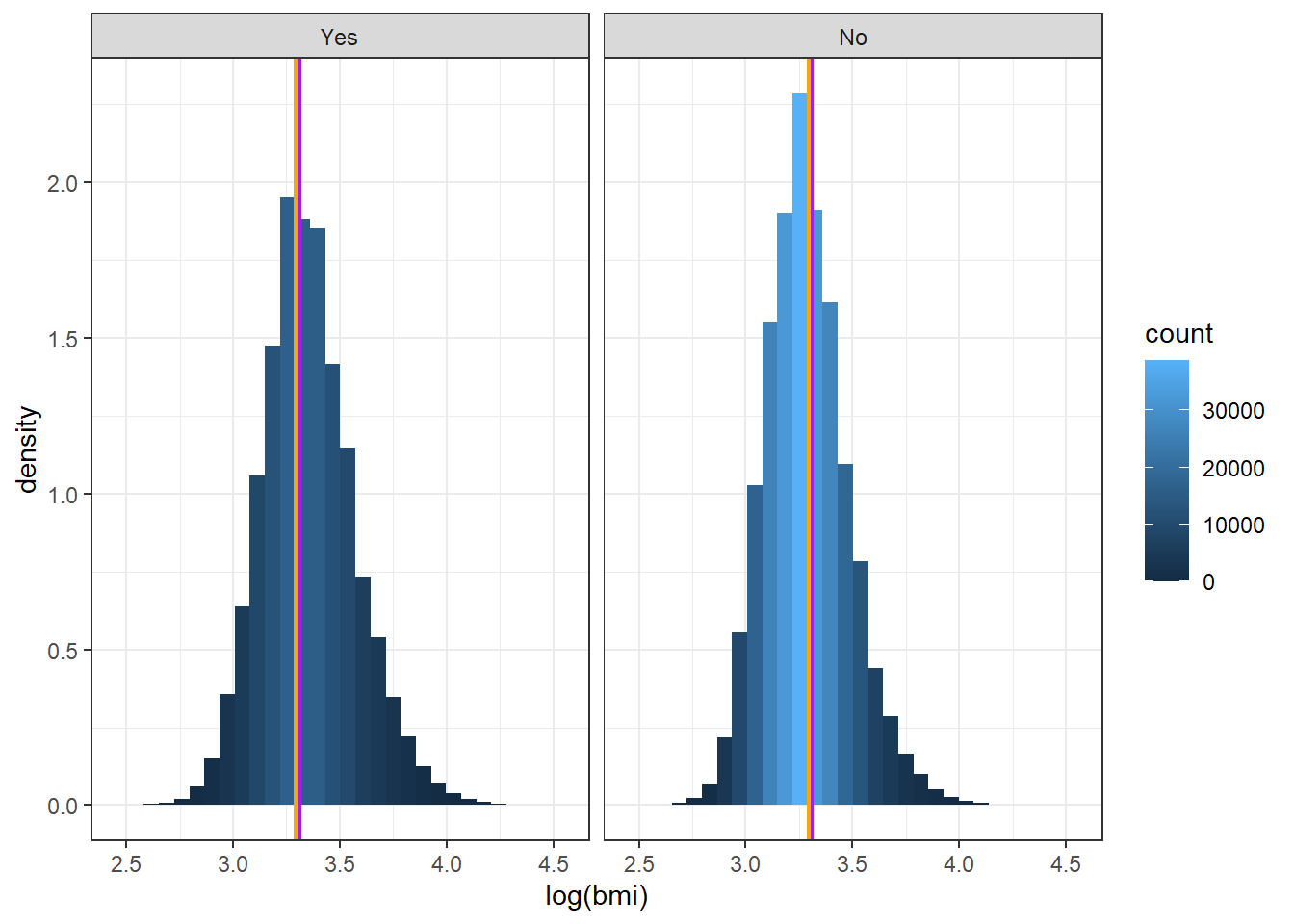
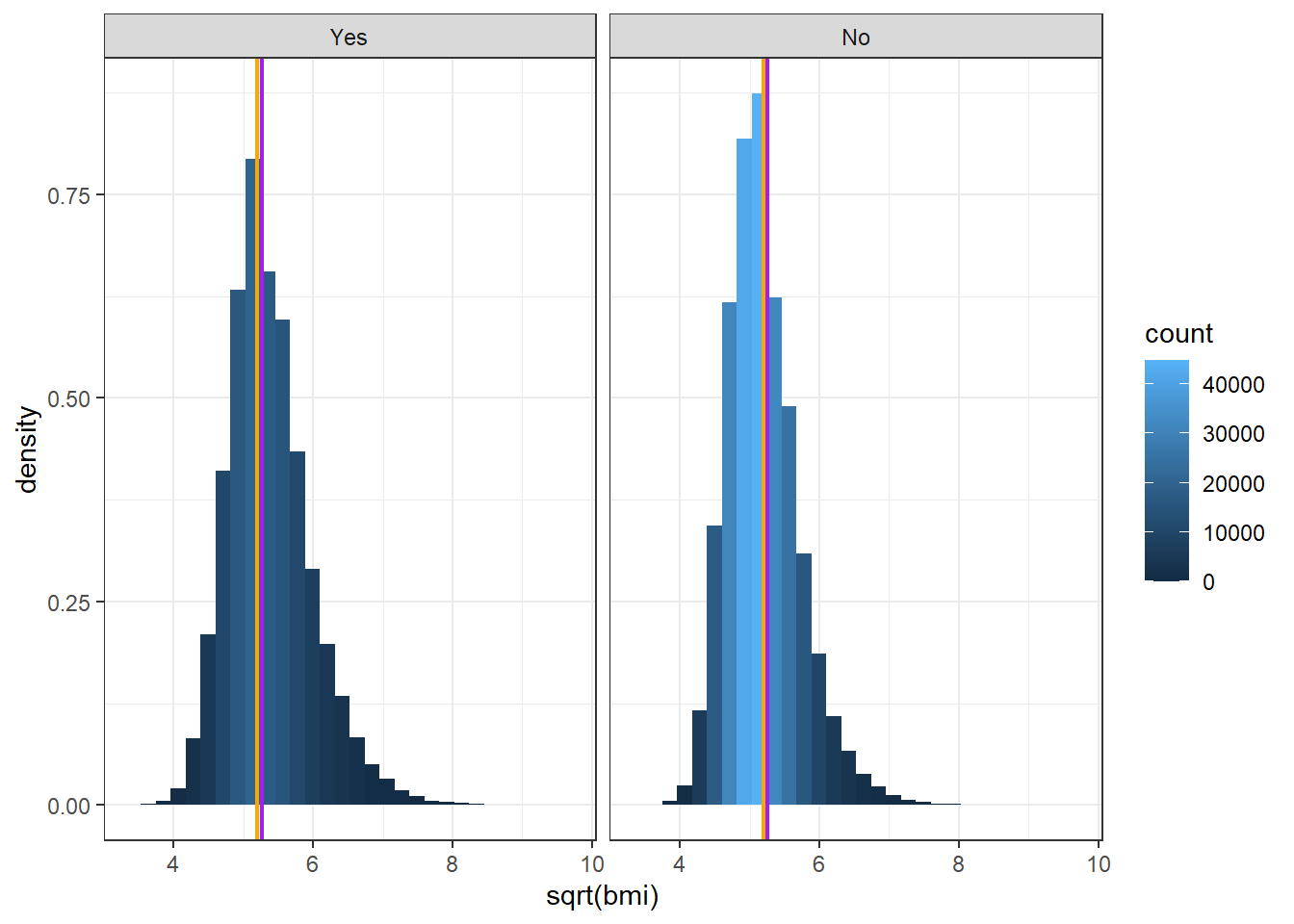
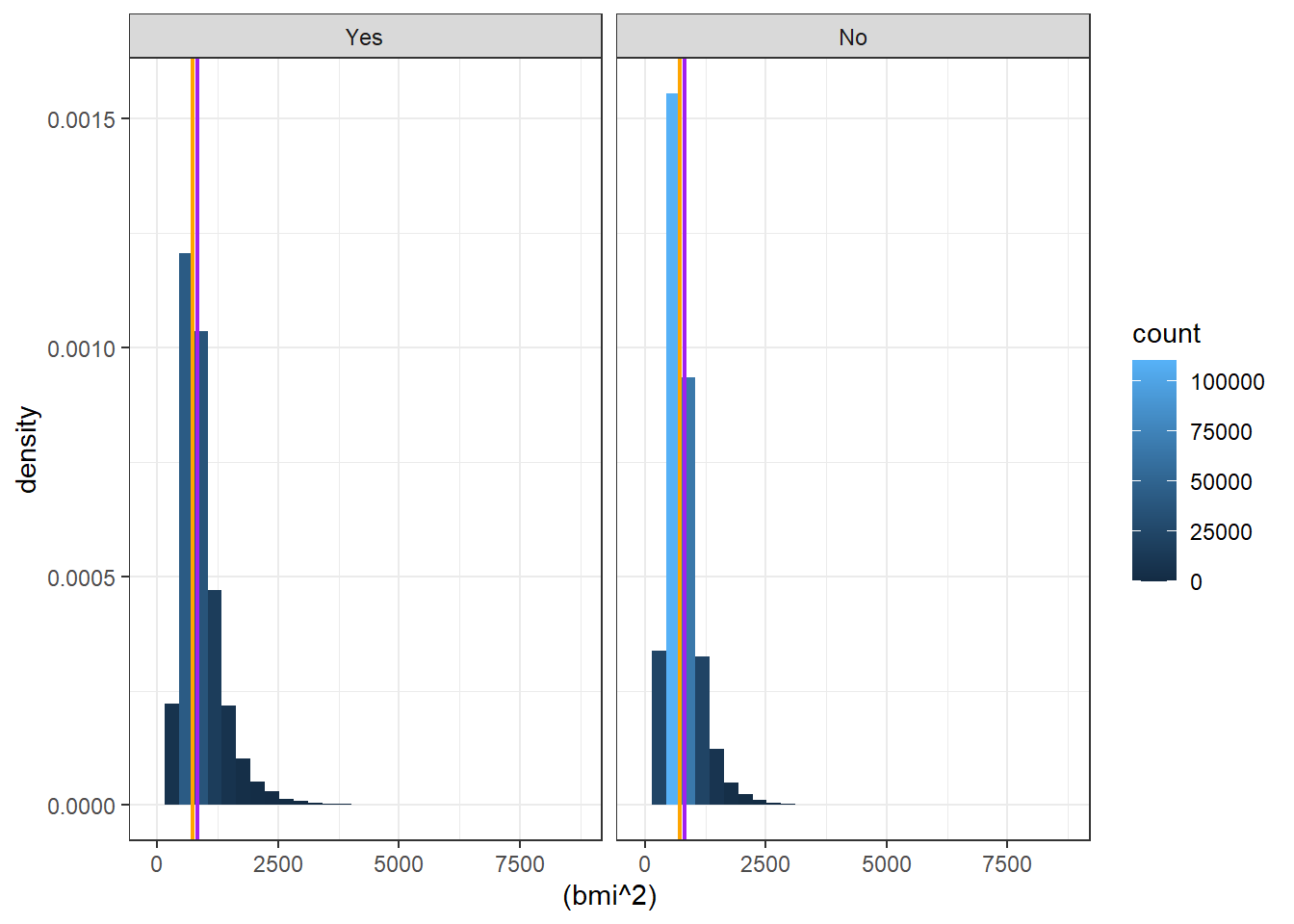
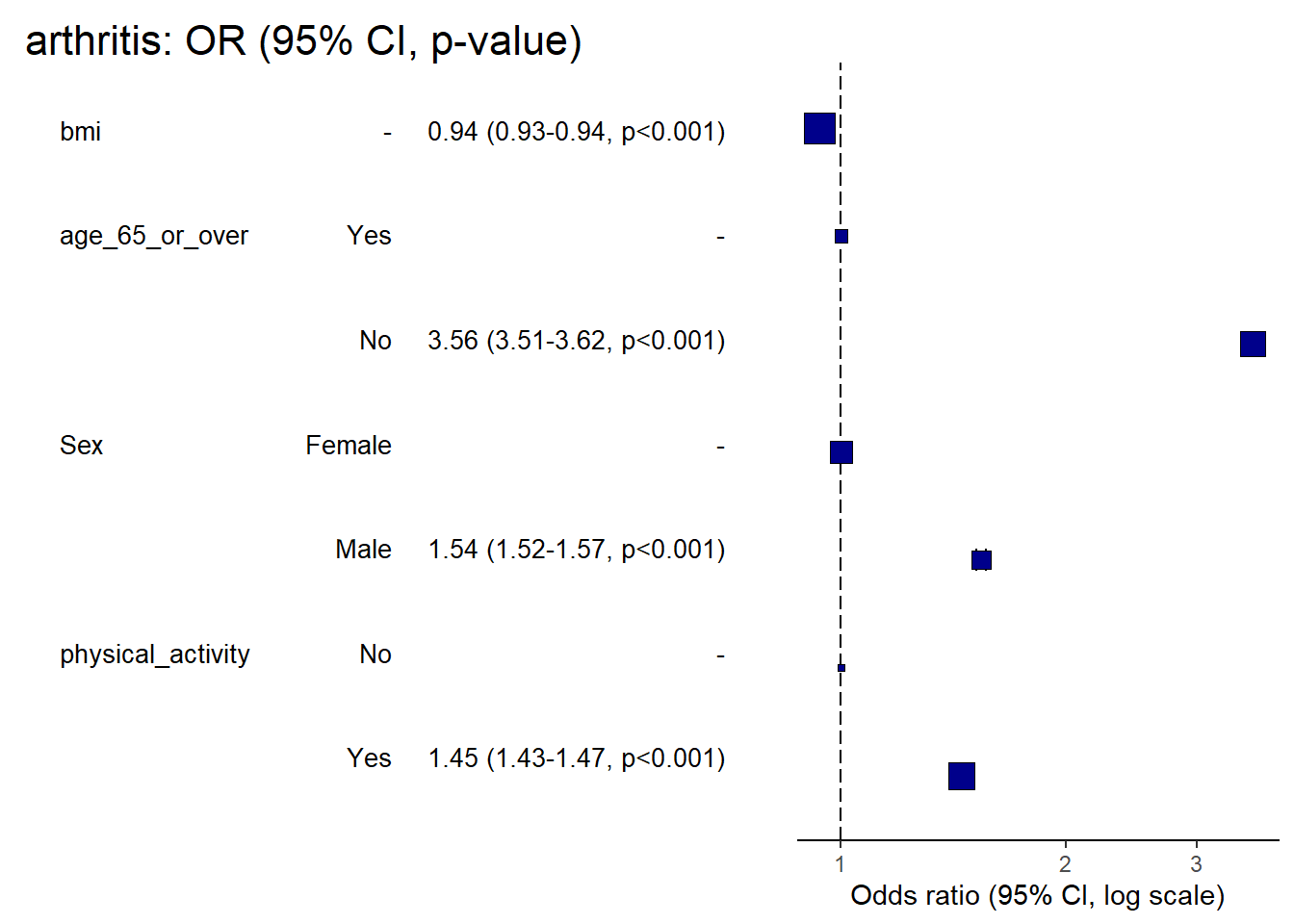
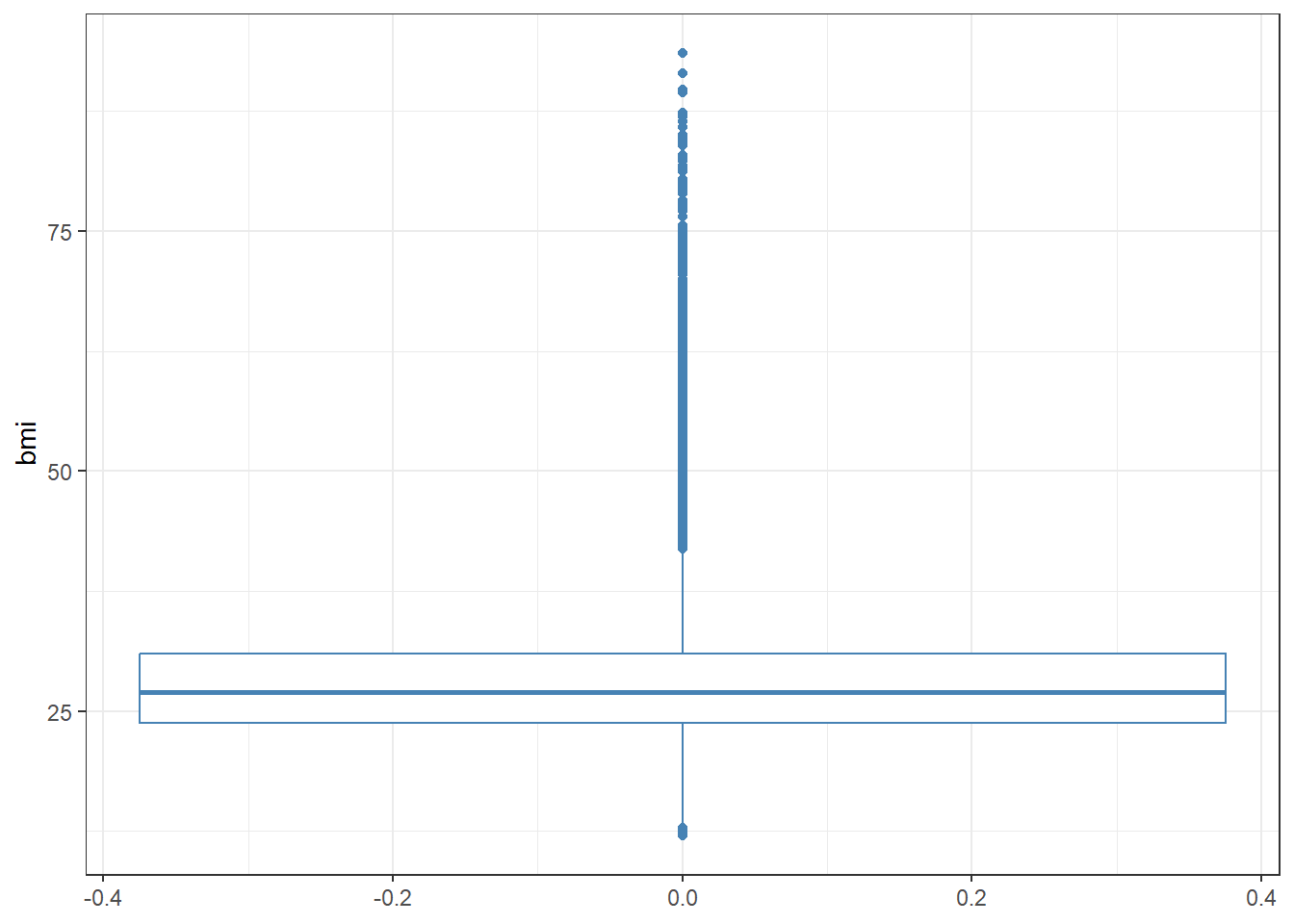Rows: 359,925
Columns: 8
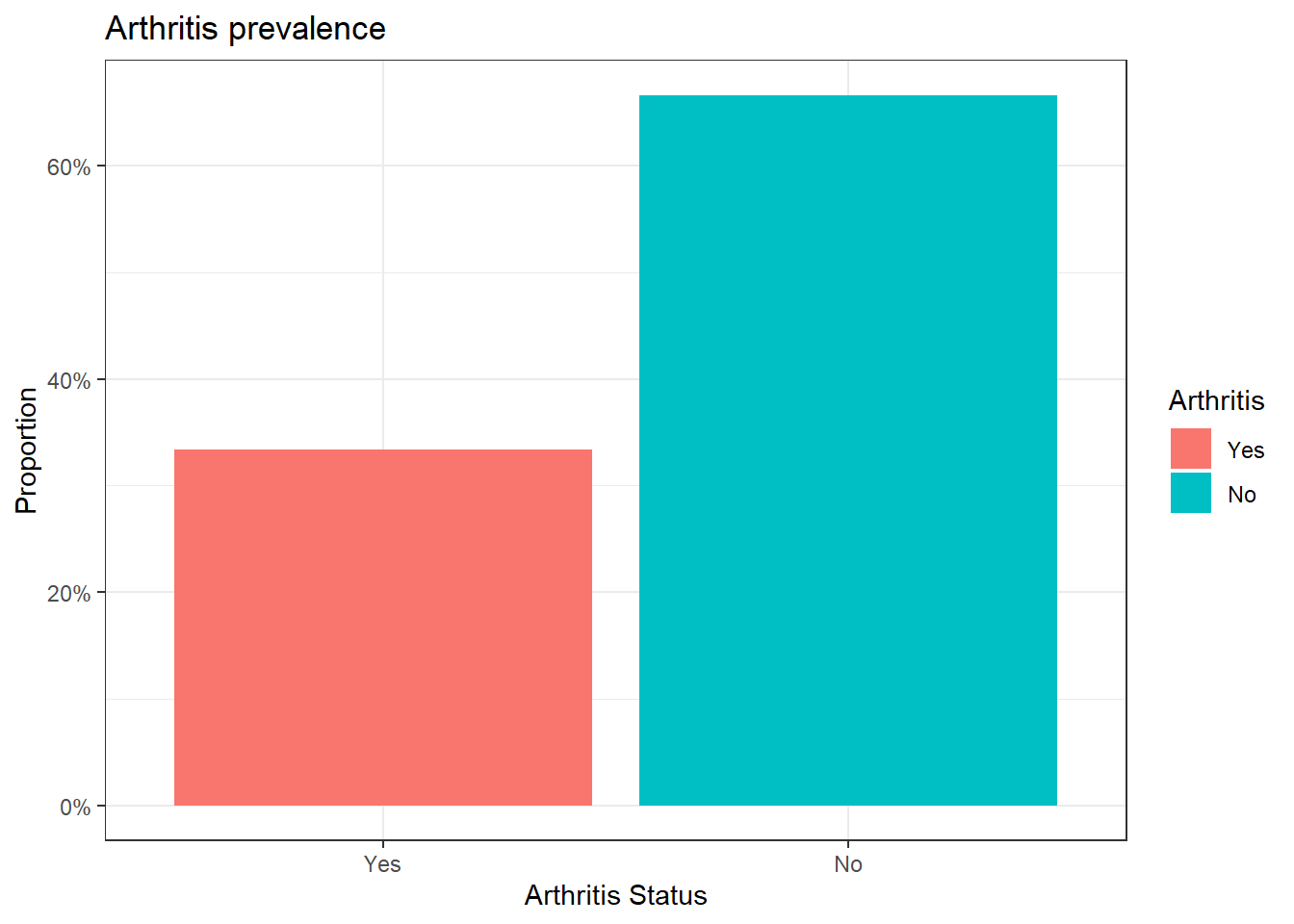
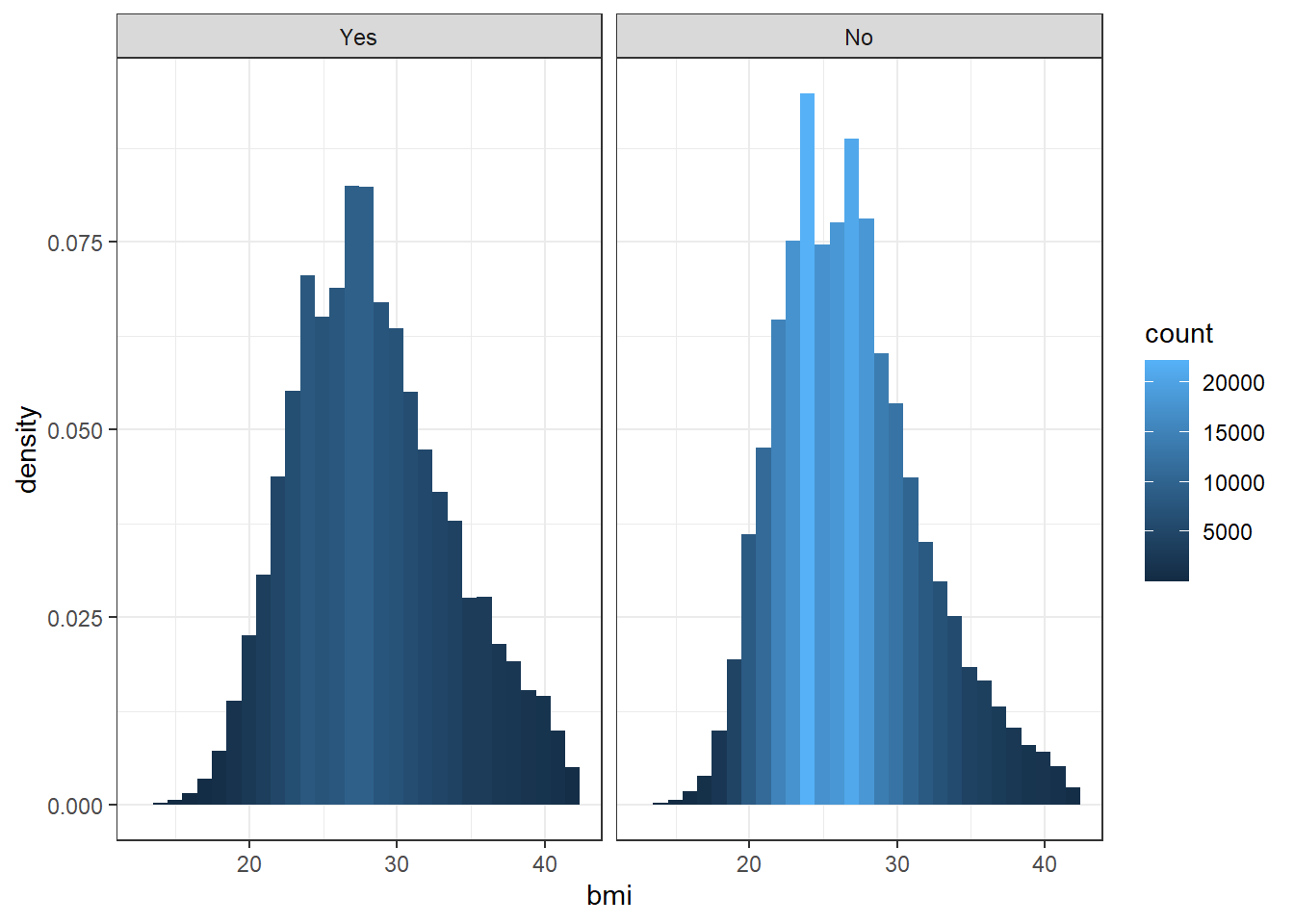
$ arthritis <fct> No, Yes, No, No, No, Yes, No, No, Yes, No, Yes, No, …
$ female <dbl> 1, 1, 1, 0, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0…
$ age65plus <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0…
$ active <dbl> 1, 0, 1, 0, 1, 1, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1…
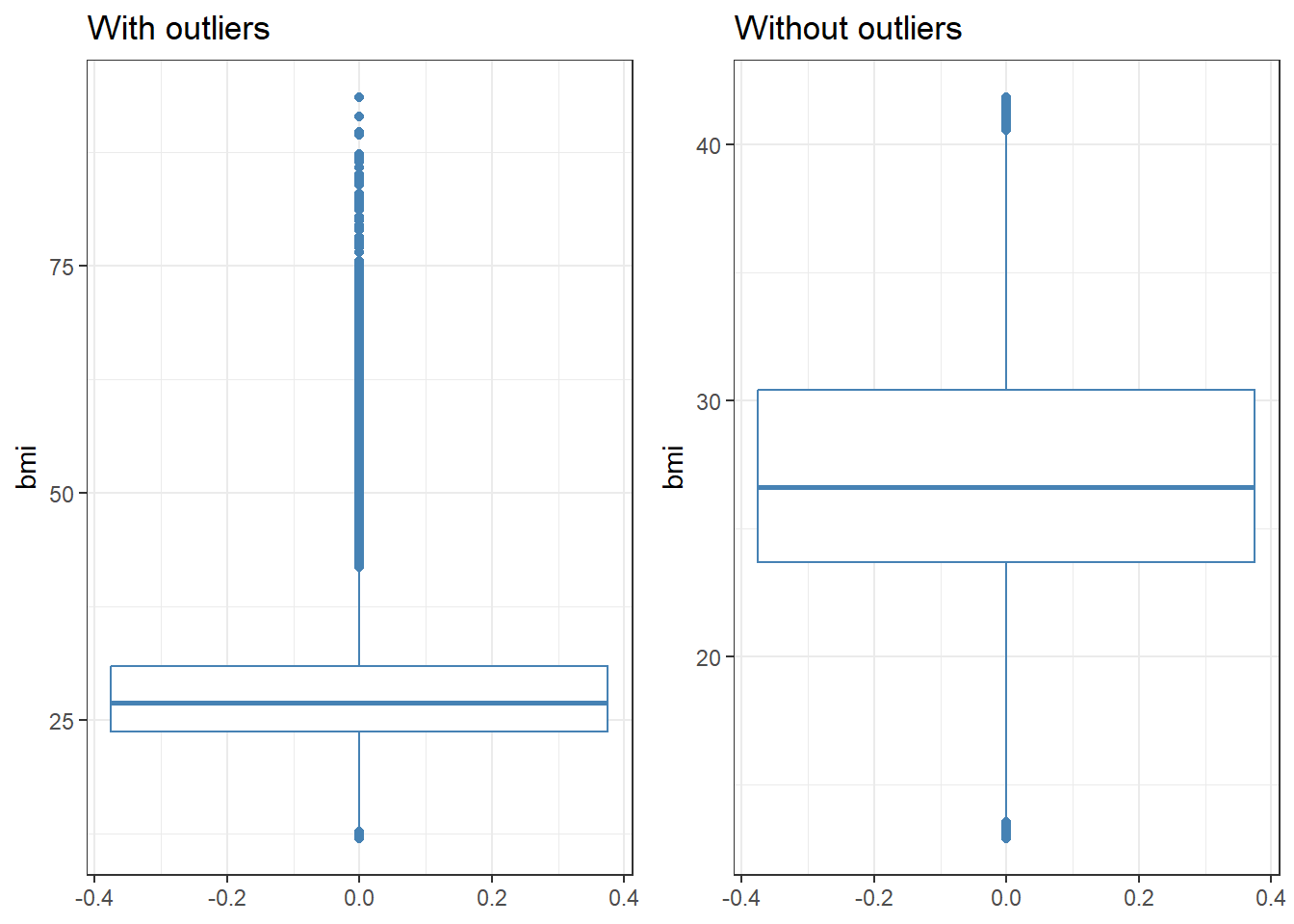
$ bmi <dbl> 18.22, 27.46, 21.97, 35.94, 39.86, 30.17, 28.29, 29.…
$ age_65_or_over <fct> No, No, No, Yes, No, No, Yes, No, No, Yes, Yes, No, …
$ Sex <fct> Female, Female, Female, Male, Female, Male, Female, …
$ physical_activity <fct> Yes, No, Yes, No, Yes, Yes, Yes, Yes, No, No, Yes, Y…